Comparison between Redis and DragonflyDB’s data stores
In this post, we will understand how Redis and DragonflyDB store the data in memory. Both of them are in-memory datastores. Redis uses a single threaded architecture which means there are no locks or synchronisation techniques required. DragonflyDB uses a multi-threaded architecture with a shared-nothing data architecture. This allows DragonflyDB to use all the cores of a system thus, allowing it to be more performant than Redis in real life use cases.
A few Primers#
A quick primer on some core concepts used in both Redis and DragonflyDB.
Separate Chaining Scheme#
Separate chaining is a collision technique where each key points to a linked list represented by the same hash value. So in cases where there are multiple keys pointing to the same hash value, the keys are inserted in the linked list.
While fetching data from the hashtable with a separate chaining scheme, the key is hashed to find the linked list where the key is stored. Once the linked list is identified, the linked list has to be traversed till the key is found.
The worst complexity to fetch a key is O(n) from a store of n elements when all the keys point to a single hashed value.
Open Addressing Scheme#
Open addressing is a collision technique where the data is stored in the next free memory space based on an offset function. The offset functions are of different types, for eg: linear probing, quadratic probing, etc.
In the case of linear probing, when a collision occurs, the data is entered into the next address slot which is free. It keeps trying to insert the data in the next slot till the table is full. In the case of quadratic probing, when a collision occurs, the next address space is defined based on the `i^2th` slot in the `i th` iteration if the given hash value x collides in the hash table.
In few examples of linear probing, the worst time complexity to fetch a key can again amount to O(n) and there are different clustering problems faced by an Open addressing scheme as well.
Extendible Hashing#
Extendible hashing is the process of using trie based key lookups to bucket pointers from the directory. This directory is flexible in size, allowing it to expand or contract based on the needs of the dataset. Each entry in the directory points to a bucket, which contains a fixed number of data entries. These buckets are where the actual data is stored. Extendible hashing uses a hash function that produces a bit string of sufficient length. However, only a portion of these bits is initially used, allowing for future expansion.
The directory is indexed by the first ‘i’ bits of the hash value, where ‘i’ is called the global depth. Each bucket has a local depth ‘d’, where d ≤ i. All entries in a bucket share the same ‘d’ bit prefix. The global depth refers to the size of the directory and the local depth refers to the key size of the bucket that it was previously mapped out to.
When inserting data, if a bucket overflows, a new bucket can be introduced, and the data from the overflowed bucket is rehashed between the 2 buckets and the rehashed buckets are added to the directory list. Addressing the bucket overflow problem is scoped to the only the bucket that is full and the other buckets are not affected, thus allowing the data structure to grow efficiently and rapidly.
Redis#
Every Redis DB contains a dict struct which holds the hash tables and other size related and hashing related information.
typedef struct dict {
dictType \*type;
void \*privdata;
dictht ht\[2\];
long rehashidx;
unsigned long iterators;
} dict;
typedef struct dictht {
dictEntry \*\*table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dictEntry {
void \*key;
union {
void \*val;
uint64\_t u64;
int64\_t s64;
double d;
} v;
struct dictEntry \*next;
} dictEntry;
The above data structures can be represented diagrammatically in the following manner:
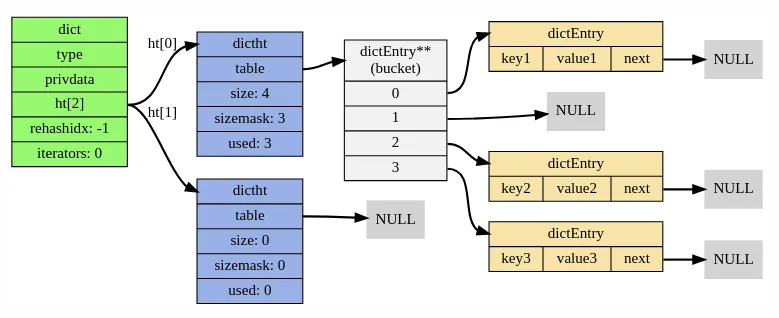
In the dict struct, we see that there are 2 dictht entries. dictht represents the hashtable with separate chaining, where the data is actually stored. dictht contains a list of pointers to the dictEntry , which is equivalent to a bucket. When a request is received with a particular key, the key is hashed to point to a specific bucket. dictEntry is a linked list which contains a key-value pair and points to the next entry in the list.
Whenever the hashtable dictht becomes full, Redis has to allocate more space to the hashtable and rehash the entire data set again. The dict struct has 2 dictht entries so that size of the dictht , which is not being used can be expanded, data can be copied over to the new dictht from the previous dictht and the data can be rehashed while bringing this up. This is an expensive operation which is conducted in a different manner in DragonflyDB’s dashtables that we will be covering later in this post.
DragonflyDB#
DragonflyDB has a similar entry point as that of Redis where it stores an array of pointers for the request to be routed to for the hashed key. This layer is called the Directory.
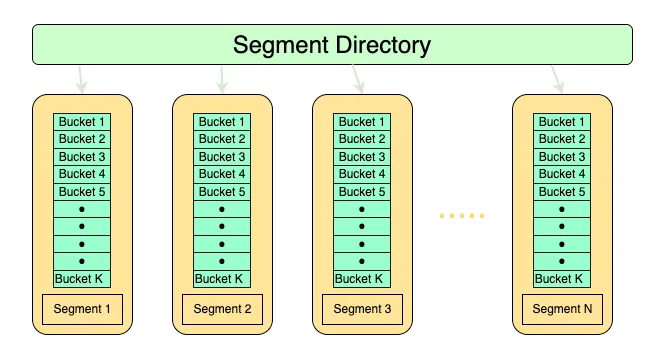
However, instead of pointing to hashtables, the Directory points to Segments , which are fixed size hashtables, i.e they grow only to a fixed size. Whenever a Segment becomes full and there is no space in the immediate next Segment, a new Segment is added to the directory. The data from the existing Segment is rehashed over the existing Segment and the newly created Segment. Extendible hashing uses a trie based approach to hash the key to different Segments. Since it uses a trie, the blast radius of rehashing a Segment only falls to the existing Segment and the new Segment since other hashes won’t be affected. In such cases, Redis usually has to do full rehash of the existing data, which is an expensive operation.
Each Segment consists of 60 buckets and each bucket contains 14 slots. This means that each Segment can hold a total of 840 items. Out of the 60 buckets, 56 buckets are regular buckets and 4 of them are stash buckets. Whenever there is a spillover from the regular buckets, the data is stored in the stash bucket.
Conclusion#
Redis has been the front runner for in-memory data stores for a long time. It’s great to see other competitors like DragonflyDB innovating on multiple aspects. I will try to bring more blogs on it’s shared nothing architecture, forkless saves, locking strategies, etc.
References:#
- https://kousiknath.medium.com/a-little-internal-on-redis-key-value-storage-implementation-fdf96bac7453
- https://github.com/dragonflydb/dragonfly/blob/main/docs/dashtable.md
I hope you liked the article. Please let me know if you have any queries regarding the article. Happy reading!!