Deep Dive into Maglev, Google’s Load Balancer
I recently heard about Maglev, the load balancer that Google uses in front of most of its services. I wanted to get a short gist on the matter to understand the reason why Google had to create its own load balancer and the optimizations that they took in order to actually run a load balancer at Google’s scale. To my surprise, I couldn’t find many articles which actually brought out the main reasons for Maglev’s existence. I had no other option but to go through the research paper submitted by the Google team. This post looks to list down the elements in the load balancer which actually make it what it is to help other readers ramp up their knowledge in a short span.
A brief introduction about Maglev and some basic design principles adopted by the authors:
- Maglev is a software load balancer compared to multiple hardware load balancers to leverage the flexibility of software
- Maglev runs on commodity hardware similar to how most of Google’s infrastructure works
- Maglev is a distributed scale-out load balancer, meaning it scales by adding nodes to the cluster compared with other load balancers scaling up their machines and deploying clusters only in high availability modes
- Maglev uses connection tuples (source IP, destination IP, source port, destination port, protocol) to redirect an user to the appropriate Maglev instance where it keeps a track of the connection and the backend services
- Maglev looks to pass traffic at line rate, which is currently 10Gbps, limited by the NICs in their current machines
- Maglev assumes that the incoming packets will be smaller in size which means that packet fragmentation, though possible, will not be the norm and thus hashing based on the connection tuple becomes optimal
- Maglev assumes that the outgoing packets can be larger in size which means Maglev adopts Direct Server Return (DSR), which is a standard way for load balancers to offload the load to the actual servers instead of the load balancer bearing the brunt
- Maglev uses a Maglev hashing, which is derived from Consistent Hashing. Consistent hashing is useful to ensure that traffic restructuring across the cluster is limited when nodes crash. Though important for a load balancer, Maglev hashing gives a higher priority to ensure that the load is distributed across all instances.
- Maglev tries to avoid cross thread synchronizations to avoid the performance complexity of maintaining synchronous data structures
- Maglev keeps track of the health of the backend services and use this data to select the backend service for the required traffic
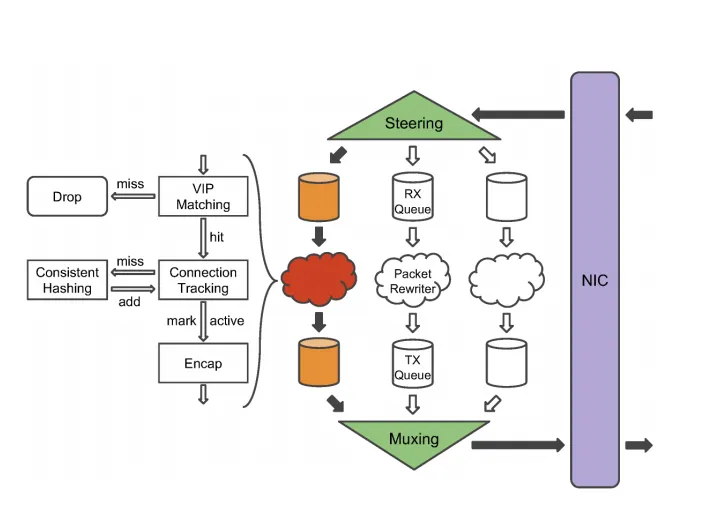
Some terminologies and modules listing before we start
- Backend Service
- Google Routers
- Maglev Controller
- Maglev Forwarder
- Magler Steering module: Part of Maglev Forwarder
- Magler Multiplexer module: Part of Maglev Forwarder
Each backend service of Google, which can Gmail, youtube, etc hosts a VIP (virtual IP). Maglev broadcasts the VIP to the Google Router sitting in front of it and the Google Router broadcasts it to the Google backbone which in turn publishes the networks to the ISPs. In case of multiple shards of the same cluster, the VIP distribution is done accordingly based on performance and isolation decisions.
Steering Module
- Calculates the 5 tuple hash of the packet and assigns it to receive queues which are listened to by packet rewriter threads
- Packet rewriter threads ensures that the packet belongs to the VIP otherwise is dropped
- The packet rewriter thread then calculates the connection hash again and checks whether it’s an existing connection or a new connection. Each packet rewriter thread manages its own connection hash association with the backend
- Once the backend is found, the packet rewriter thread encapsulates the packet using GRE and sends it to the Transmission Queue
- In cases where a particular receive queue becomes full, the Steering module resorts to round robin scheduling instead of connection hashing to ensure that the load is evenly distributed
Muxing module
- The muxing module listens on the transmission queues, and forwards the packets towards the NIC
Fast Packet Processing
- Maglev is an userspace application
- In a normal linux server, packets are received by the kernel and de-encapsulated or encapsulated (based on the direction) layer by layer with possible memcopy at various places. In order for Maglev to operate on a standard linux server, the kernel would have to copy packets back and forth the Maglev service which would be computationally expensive
- Since Maglev’s functionalities are very narrow, the authors took apart the entire Linux kernel networking stack and replaced it with their own packet processing logic to avoid redundant checks
- Maglev prevents any cases of data copying of packets entirely to prevent memory bloating and saves CPU cycles
- Maglev preallocates the entire packet pool depending on the instance size. All Maglev components use pointers towards the packets in the packet pool to maintain their business logic
- There are multiple pointers types which help the Maglev forwarder components to maintain state
- Received — When the packets are received from the NIC
- Processed — Steering module assigns the packet to the packet writer threads
- Reserved — Collects the unused packets and stores in the reserved pool
- Sent — The packets are sent by the NIC
- Ready — Muxing module sends the packets to the NIC
- Batch operations are preferred whenever possible to minimize boundary-crossing operations
- Each packet rewriter threads runs on a single CPU to prevent CPU multiplexing and context switches
References:
- https://storage.googleapis.com/pub-tools-public-publication-data/pdf/44824.pdf
- https://medium.com/martinomburajr/maglev-the-load-balancer-behind-googles-infrastructure-architectural-overview-part-1-3-3b9aab736f40
- https://blog.acolyer.org/2016/03/21/maglev-a-fast-and-reliable-software-network-load-balancer/