Kafka, KRaft and Storage Tiers
I was recently looking at a managed Kafka service and came across services like AWS MSK and Kafka on Confluent Cloud. While comparing these services, I saw that there were limitations on the number of partitions allowed in a cluster. For example, the maximum number of partitions per broker in AWS MSK is 4000.
I wanted to understand the underlying resource crunch for the partition limit.
As I proceeded with understanding the reasons behind the same, the underlying problem came out to be a non-uniform approach of dealing with metadata in Kafka.
Kafka elements use both Kafka Controller Nodes and Zookeeper to keep track of the metadata. This leads to lots of synchronization and management overhead between Kafka elements, Kafka Controller nodes and Zookeeper.
As mentioned here,
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
Prerequisites#
Partitions and partition keys define the parallelism possible in a Kafka topic. In every Kafka consumer group, there can only be one consumer in the group which reads from a specific partition. So if you have a Kafka cluster and your consumer load is not evenly distributed, it can be a case of a bad partition key specific to your application.
Replication for partitions is configured in the cluster. Each partition has a configured number of replicas and has a leader replica and backup replicas. Writes and reads happen via the leader replica, hence it is advised to distribute the leader partition replicas across brokers to minimise the load of redistribution of replicas if one of the brokers goes down.
Each Kafka cluster has mainly the following elements which interact with the brokers:
- Producer
- Consumer
- AdminClient
Current System with Zookeeper#
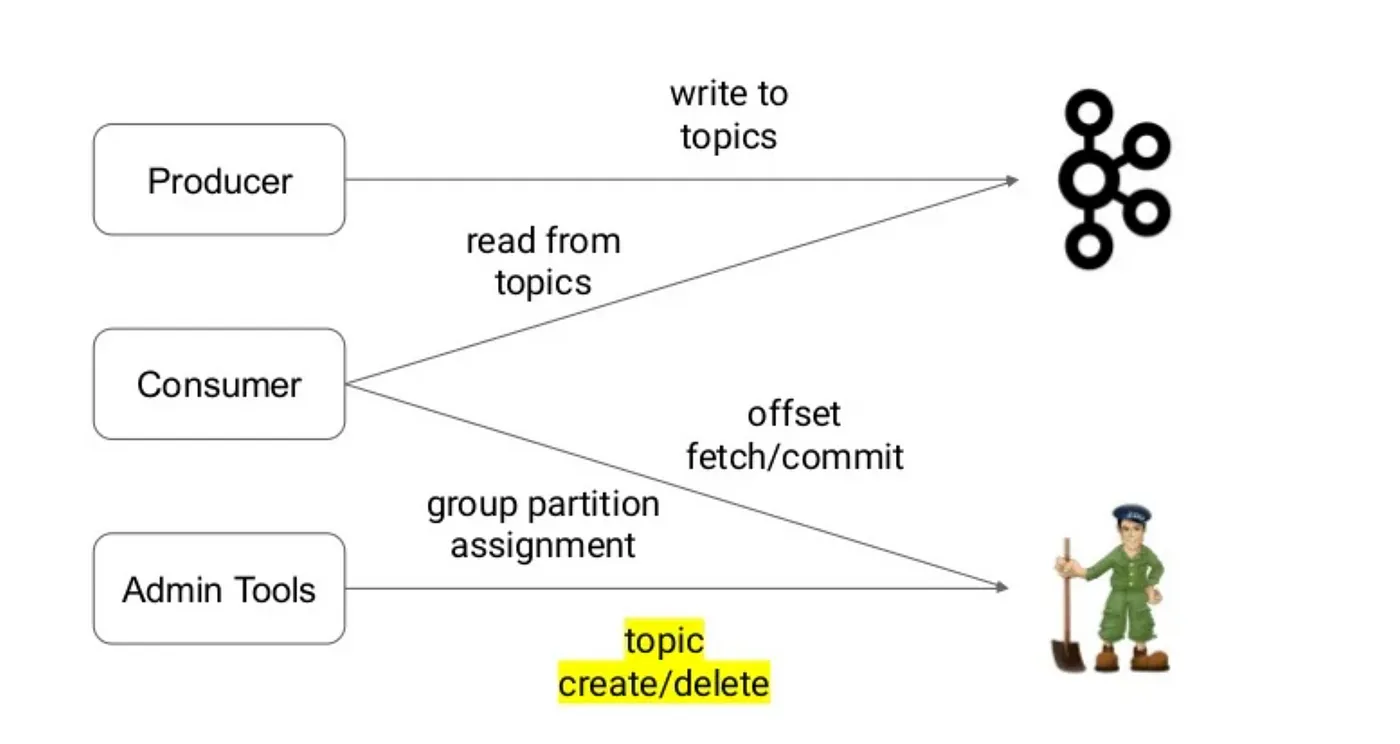
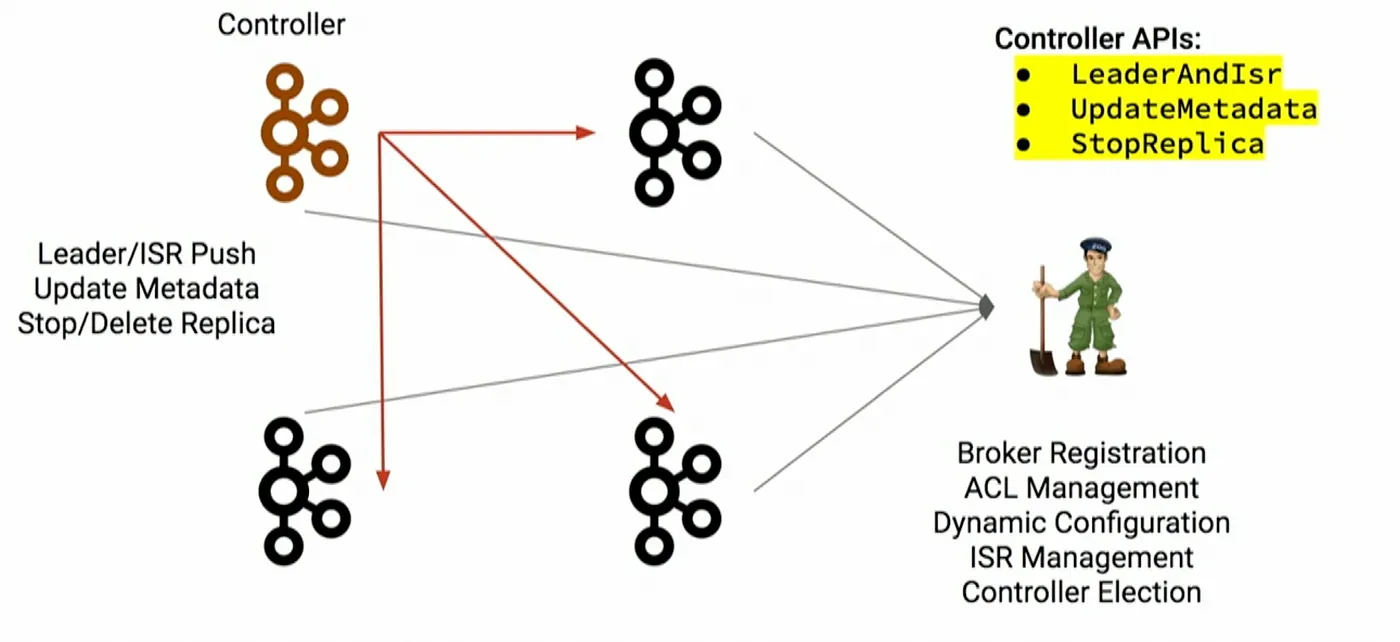
As we can see from the above system, metadata like the commit offset, group partition assignment is stored in Zookeeper and the other information is stored in Kafka.
Zookeeper maintains a map of all the brokers in the cluster and their status. Whenever a broker joins or leaves the cluster, Zookeeper has to track the change and broadcast it to the other nodes in the cluster. Updates to Zookeeper and the Controller node is synchronous but updates to the brokers is asynchronous, which may lead to race conditions.
Whenever a broker node starts up, it tries to mark itself as the Controller and sends it to Zookeeper. The Zookeeper service responds with a Controller Already available message. Whenever a broker becomes unreachable to Zookeeper, it marks the broker as unreachable and removes the entry. When the broker becomes reachable again to Zookeeper, it has to fetch all the information of the cluster again as it has no concept of deltas and the previous information already present with the broker.
When a Controller node goes down or is restarted, it has to read all the metadata for all brokers and partitions from ZooKeeper and then send this metadata to all brokers. This results in a n*m operation (where n is the number of brokers and m is the number of partitions).
When a network partition happens for a broker and is unreachable to either the Controller node or Zookeeper, fencing kind of becomes difficult or expensive to have.
Proposed System with kRaft#
More about Raft here.
Raft is a consensus algorithm that is decomposed into relatively independent subproblems, and it cleanly addresses all major pieces needed for practical systems. Consensus is a fundamental problem in fault-tolerant distributed systems which involves multiple servers agreeing on values.
Kafka serves as a distributed commit log which can be used for various purposes like message queues, streaming, audits, etc.
The fundamental advantages of a log based system are:
- Logs are append only
- Different readers can store their own offset
All other advantages like caching, maintaining epochs, replays, audits, efficient backups, delta reads are a side effect of the above fundamentals.
Once the Kafka team started looking at the comparisons between the Raft and Kafka commit logs, they came up with the below image:
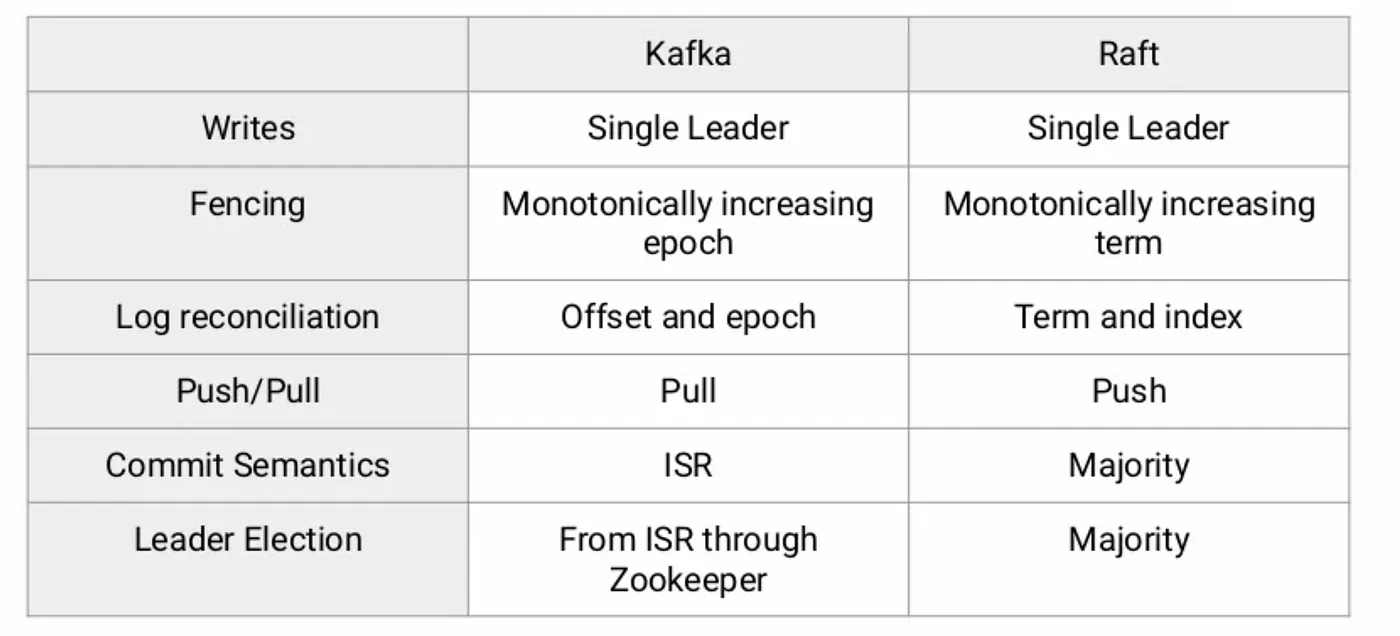
Keeping the above table in mind, the Kafka team introduced a new consensus based protocol called kRaft where metadata is stored as a commit log. More details on the same here.
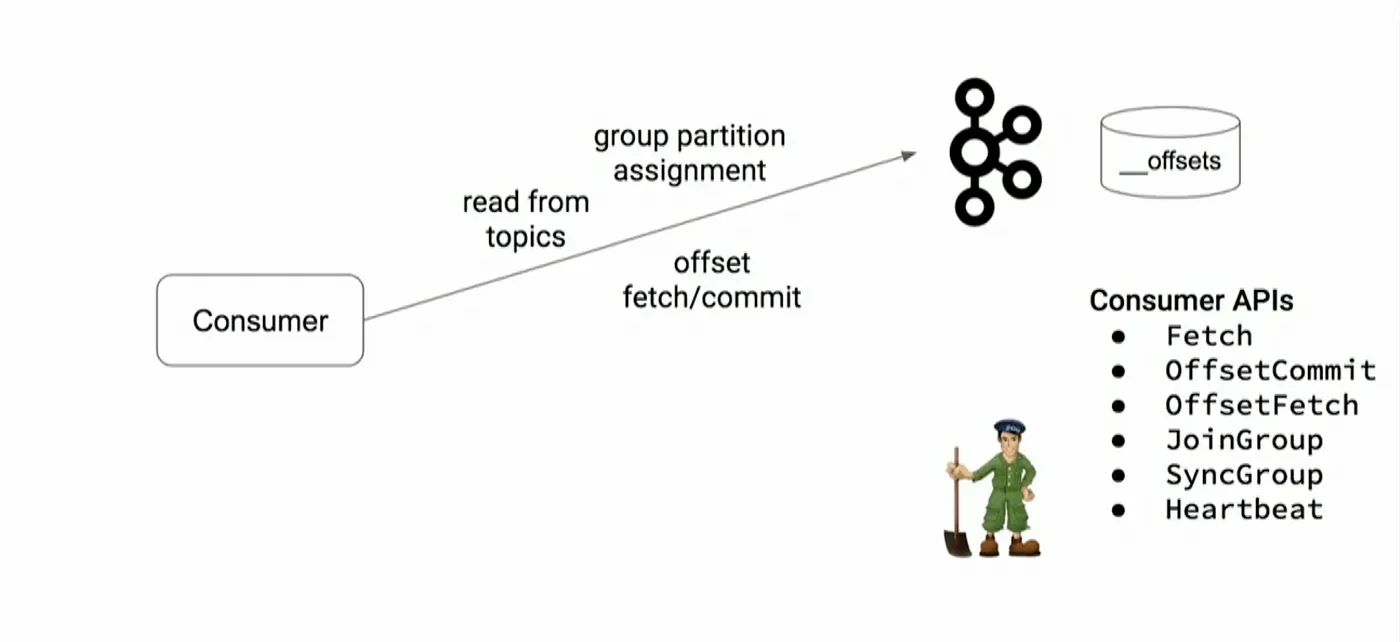
Instead of storing metadata like partition assignment, commit offsets, etc in Zookeeper, Kafka uses internal Kafka topics like __offsets to store the metadata information.
Internal APIs like OffsetCommit, OffsetFetch, JoinGroup, SyncGroup, Heartbeat, etc are now handled by Kafka itself instead of sending it to Zookeeper.
Instead of ad-hoc message passing across the brokers, the brokers can now consume the messages in the logs and process them. As the messages are processed, the brokers keep themselves up to date.
If the broker becomes unreachable for a certain duration, once it is up, it can process the messages from the internal topics and once it has processed the messages, it can again be marked as active. Only the delta messages needs to be processed which results in a significant decrease in time required to rejoin the cluster.

There are specific controller nodes (usually 3 to 5) which maintain a self managed quorum to decide the leader. If the leader controller goes down, the backup controller can almost instantly take over once its messages are up to date.
All of the above items reduce the load of partitioning and overall, the load of maintaining metadata across large clusters.
Storage Tiers in Kafka#
Kafka mainly uses disks for log retention. The size and speed of the disks required is dependent on the retention period configured on the data. Because of Kafka underlying ability to replay messages from the start, different applications use the ability of configuring longer retention periods.
However, having longer retention periods also has its own strain on the disk in terms of backups, migration, etc. This increases the risk on consumers on the same cluster which depend on the fairly recent messages and don’t need a longer retention period for more than 2–3 days.
The Kafka team has come up with a concept of local storage tier and remote storage tier to alleviate the problem.
The retention period and the disk type can be configured separately for the different tiers. For example, for the local storage tier, we can use a smaller 100 GB SSD disk with a retention of 2 days. For the remote tier, we can use HBase or S3 with a retention period of 6 months.
For applications which need older data then the data in the local storage, the Kafka brokers will itself talk to the remote tier and fetch the data accordingly. This allows the same Kafka cluster and topics to serve different kinds of applications.
References
- https://docs.confluent.io/platform/current/zookeeper/kraft.html
- https://www.confluent.io/kafka-summit-san-francisco-2019/kafka-needs-no-keeper
- https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum
- https://www.amazon.in/Kafka-Definitive-Guide-Neha-Narkhede/dp/1491936169