Neo4j storage internals
I was exploring Neo4j and came upon this video where Jim Webber, Chief Scientist at Neo4j, explains these numbers:
125x = 48y = 3z is the ratio of the cluster size(number of instances) required for a similar data store functionality where x=MongoDB, y=Cassandra and z=Neo4j
and
20x = 50y = 0.33z is the ratio of the disk size required for a similar data store functionality where x=MongoDB, y=Cassandra and z=Neo4j
The blog post will look to cover the internals of how the data is stored and accessed in Neo4j and why it is a serious contender for a certain type of data storage.
Before going further, let us explore how MySQL would handle nodes and relationships internally and the affects of it as the data size grows.
Suppose we want to build the feature where users can like a post in facebook. Following tables will be required:
- Users (containing user information)- ID, Name, Email, etc
- Posts (containing post information)- ID, URL, Content
- Likes (is a table containing the many-to-many relationships)- UserID, PostID
We would ideally index the UserID and PostID columns belonging to the likes table. Let’s try to find the posts that a particular user has liked. First, we have to find the user account using the UserID from the users table. In order to find the posts on which the user has liked, MySQL follows the join based approach where it joins the likes table and the users table using the UserID column and that leads a scan of all the indexes of the table which becomes expensive as the table grows. This is a first level relationship. The cost becomes more expensive as the the degree of the relationship grows as there is a need of joining multiple tables which is not really efficient and doesn’t guarantee a O(1) complexity.
One of the major differences that a graph database like Neo4j provides is index free adjacency, which means that there is no requirement of having indexes and looking them up in order to match and form relationships. We will get to how Neo4j does it in some time.
The index style of finding relationships is also one way, i.e it will take separate queries to find the relationship in the opposite direction. The relationships are not bidirectional, whereas in graph databases, the bi-directional nature of the relationships are out of the box since it follows a more natural way of linking relationships.
Neo4j uses a fixed record size based pointer scheme to to store graph data thus, providing O(1) traversal
— Jim Webber
Neo4j entities:
- Node
- Relationship
- RelationshipType
- Property
- Label
The attributes/properties of a node and the relationships are separated out so that they are not treated in the same manner. It is important to segregate the value and reference of the nodes in order to provide optimal storage and access for both of them.
Each of the entities have their own store file in neo4j. For example, all the nodes are stored in the node store file which is neostore.nodestore.db for Neo4j. All relationships are stored in the relationship store file which is neostore.relationshipstore.db for Neo4j.
All records of any type in neo4j are fixed sized records, thus allowing easy and efficient mathematical formulas to access the record without the need for traversal.
Node store:
All the nodes in the database are stored in the node store file.
Each node record accounts for a fixed 15 bytes.
The layout is as follows:
- 1st byte — isInUse
- Next 4 bytes — ID of the node
- Next byte — First relationship ID
- Next byte — First property ID
- Next 5 bytes — Label store
- Remaining byte — for future use
The first byte is used to determine whether the record is being used or has been deleted. If not, the record will be used for newer entries.
The next 3 sectors are the IDs of the node itself, first relationship ID, first property ID and label store. Some of the labels are stored in the node itself if possible for lesser jumps. The other bytes are to saved for future use.
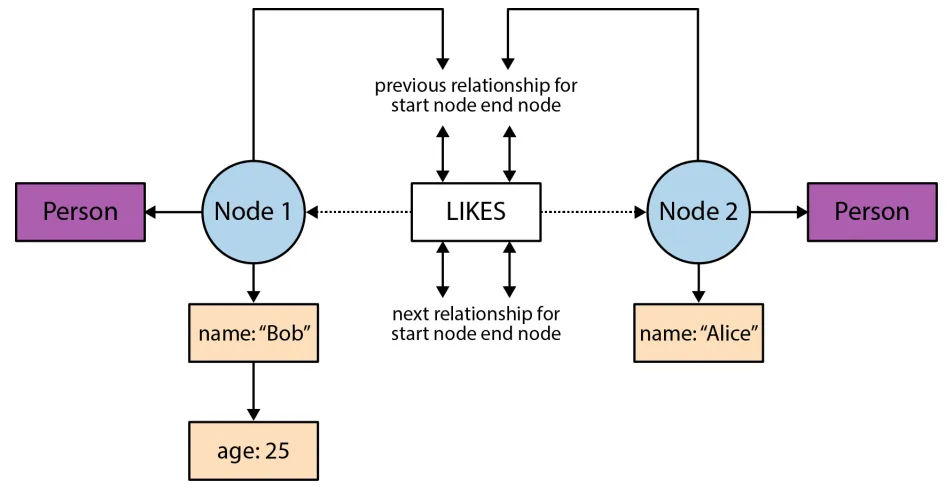
Relationship store:
Each relationship record is a fixed record of 34 bytes
The relationship record’s layout is as follows:
- Start node ID
- End node ID
- Pointer to the relationship type
- Pointer to the next and previous relationship record for each of the start node and end node
Each relationship record belongs to two nodes, the start node and the end node. Each relationship also has a type associated with it, which signifies which type of relationship is connecting the 2 nodes. The pointer to the relationship type helps to determine this.
The relationship node contains 4 other pointers or misdirections to relationship records. They point to the previous and next relationship of both the start node and end node similar to how doubly linked lists behave.
Neo4j uses trees to provide indexing capabilities to reach the start node from where we can start the traversal.
To reach the appropriate node, we have to iterate through the relationship linked list from the start node, iterate till we find the appropriate the required relationship record, and then apply the formula to find the appropriate node from the relationship record.
As we see from the above description, the fixed sized records and pointer type traversal instead of scanning the table using indexes lead to much faster and efficient way of finding relationships.
Once we find the start node record, using the first relationship ID, we can find the relationship in the relationship store by multiplying the ID with the size of the relationship record. We can get the relationship record and from that we can find the second node in the node store using a similar formula.
The Property Store and the Label store are simpler stores similar to node store.
The Neo4j engine also has a LRU k-page cache which basically divides the cache into segments based on the different types of store files and keeps a fixed count of records in these segments by removing the least recently used records.
Below are some numbers taken from the Neo4j site:
Scenario #1 — Initial status
- Node count: 4M nodes
- Each node has 3 properties (12M properties total)
- Relationship count: 2M relationships
- Each relationship has 1 property (2M properties total)
This is translated to the following size on disk:
- Nodes: 4.000.000x15B = 60.000.000B (60MB)
- Relationships: 2.000.000x34B = 68.000.000B (68MB)
- Properties: 14.000.000x41B = 574.000.000B (574MB)
- TOTAL: 703MB
Scenario #2–4x growth + added properties + indexes on all properties
- Node count: 16M nodes
- Each node has 5 properties (80M properties total)
- Relationship count: 8M relationships
- Each relationship has 2 properties (16M properties total)
This is translated to the following size on disk:
- Nodes: 16.000.000x15B = 240.000.000B (240MB)
- Relationships: 8.000.000x34B = 272.000.000B (272MB)
- Properties: 96.000.000x41B = 3.936.000.000B (3936MB)
- Indexes: 4448MB * ~33% = 1468MB
- TOTAL: 5916MB
References: