Understanding Monarch, Google’s Planet-Scale Monitoring System
Monarch is a planet-scale in-memory time series database developed by Google. It is mainly used by as a reliable monitoring system by most of Google’s internal systems like Spanner, BigTable, Colossus, BlobStore.
As is the case with any Google service, it has to be designed for massive scale, highly available, support regional locality. Another use case that was important for Monarch was to depend on other Google services as little as possible since other services were using Monarch for their own monitoring and any outage in either would affect the other as well.
Monarch is a service that has to be highly available and partitioned, hence it compromises the consistency by providing the required hints to the client service in cases of consolidating consistency delays.
Monarch tries
Data stores:#
The data is stored in two formats:
- Leaves are the components where the actual monitoring data is stored in memory
- Logs are persistent stores that can be used to replay the events in case of component failures
Data Ingestion#
The data ingestion pipeline tries to follow the below guidelines:
- Store data of the client service as close to the service’s operating region as possible so that network latency is minimal
- Store data of client service in the same leaf as there is a high probability of data queries being clubbed and focussed on that leaf for faster query responses
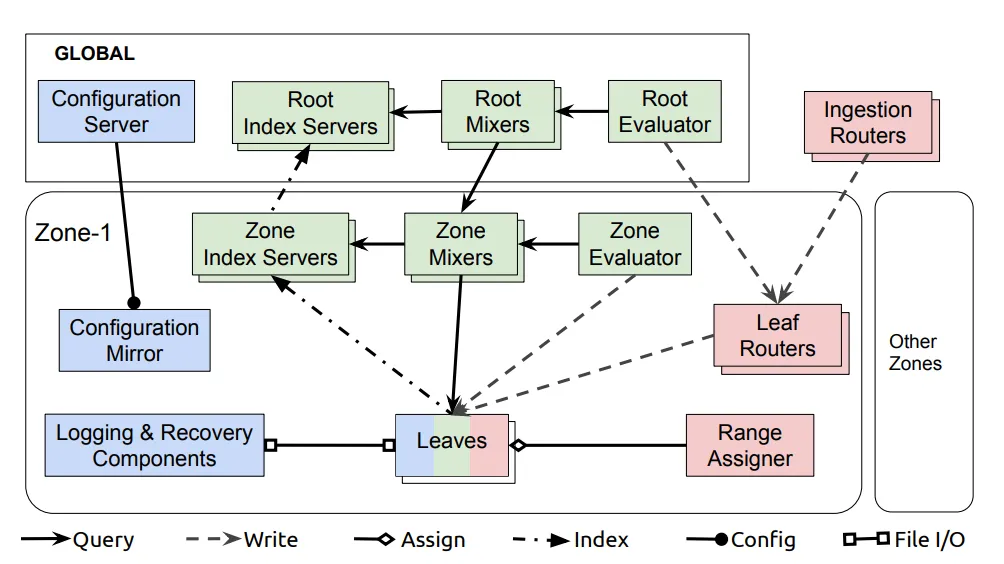
The data traversal will happen in the following approach:
- Ingestion Router routes the data to the leaf routers
- Leaf Routers routes the data to the leaves
- Range Assigner decides the leaf to store the data
Ingestion routers regionalize time series data into zones according to location fields, and leaf routers distribute data across leaves according to the range assigner
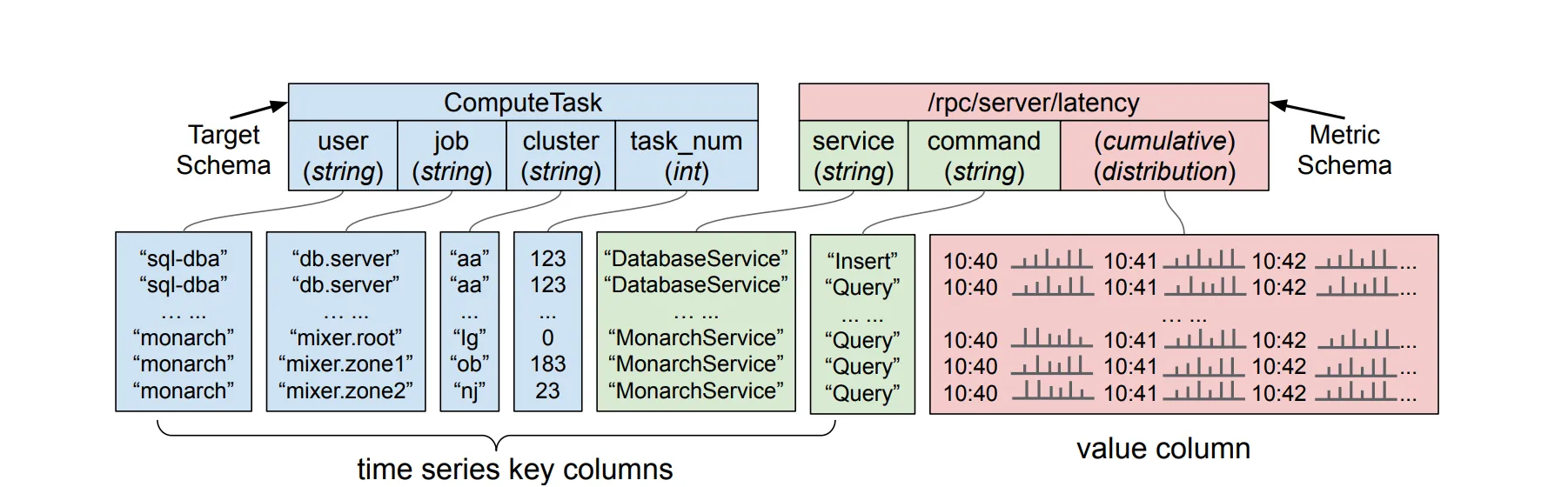
The data received has the following categories:
Targets are used to identify the node/service/component form which the data has generated. Based on the above diagram, a Target string ComputeTask::sql-dba::db.server::aa::0876 represents the Borg task of a database server. The format of target strings is important in data placement among the leaves as target ranges are used for lexicographic sharding and load balancing among leaves.
Metrics contain the metric information in the format of key-value pairs where keys are the type of metrics of a target and the value is time series based data points. The metric types supported are boolean, int64, double, string, distribution, or tuple of other types. The metric values can be cumulative or a gauge. The advantage of using cumulative points is the intermittent data losses don’t affect the distribution by much.
The data can be sent in Delta Time Series where only the delta in the time series data is sent instead of the whole metric. This reduces the continuous input of data and requires handling only there is a change in the data range.
Bucketing helps to aggregate data points for a certain duration before sending them to the ingestion pipeline. This reduces the network handling and bulk inserts can be performed.
Admission windows are used to reject queries that are received after a certain duration so that the pressure of handling data received after a certain duration can be avoided.
Data Querying#
Monarch provides a globally federated query engine. All queries can be fired at the global level and Monarch takes care of routing the query to the leaves where the relevant data is stored and consolidates the responses from the leaves.
Components used in data querying which can be viewed in the above diagrams are as follows:
- Mixers break down the queries into subqueries and consolidate the responses from the subqueries. Root mixers receive the queries and fan them out to zone mixers which further fan it out to the leaves, thus forming a Query Tree. The Mixers also check the Index servers to limit the queries to the zones or leaves where the data resides in
- Index servers index the data for each zone and leaf which can be used to understand which leaves the queries are meant for
- Evaluators generate the responses from Standing queries and write the data back to the leaves
Monarch’s Query Language supports the following keywords:
- Fetch
- Filter
- Join
- Align
- GroupBy
Ad-hoc queries are queries that are from users outside of the system.
Standing queries are queries that are similar to views in other database systems. The standing queries are periodically calculated and stored back into Monarch for faster query responses.
Standing queries are also more performant since the evaluation can be done at the zone or root level depending on the breadth of the query. This minimizes the query space to region-specific leaves.
Level analysis of the query is done which breaks the query based on various levels for authentication and better query locality. The levels can be defined based on the Query Tree mentioned above.
Replica Resolution is used to figure out the best replica to answer the query as there may be differences in query load, system configuration, etc which makes a certain replica better suited for responses.
User Isolation limits the amount of memory any user can use in the system so that other rule-abiding users are not affected.
Performance#
- Monarch runs on 38 zones spread across five continents. It has around 400,000 tasks
- As of July 2019, Monarch stored nearly 950 billion time series, consuming around 750TB of memory with a highly optimized data structure
- Monarch’s internal deployment ingested around 4.4 terabytes of data per second in July 2019
- Monarch has sustained exponential growth and was serving over 6 million queries per second as of July 2019.

I hope you liked the article. Please let me know if you have any queries regarding the article. Happy reading!!
References: