MVCC and serializability in HyPer
In the realm of database management systems, the ability to handle concurrent transactions efficiently is paramount. As applications demand higher performance and seamless user experiences, traditional locking mechanisms often fall short, leading to bottlenecks and reduced throughput. Enter Multi-Version Concurrency Control (MVCC) — a technique that allows multiple transactions to access data concurrently without interference.
Before going deeper into MVCC, let’s cover Two Phase Locking and why MVCC is a better choice to maintain concurrent transactions.
Two phase locking#
Two-Phase Locking (2PL) is a widely used concurrency control protocol in database management systems that ensures conflict-serializability. It operates in two distinct phases: the growing phase and the shrinking phase. Here’s a detailed explanation of how 2PL works, its types, and its implications in transaction processing.
Growing Phase
- In this phase, a transaction can acquire locks but cannot release any locks. The transaction continues to request and obtain the necessary locks on data items until it reaches a point known as the lock point, where it has acquired all the locks it needs for its operations.
- The primary goal during this phase is to ensure that the transaction has exclusive access to the data it needs to read or write.
Shrinking Phase
- Once the transaction reaches its lock point and completes its operations, it enters the shrinking phase. In this phase, the transaction can release locks but cannot acquire any new locks.
- This ensures that once a transaction starts releasing locks, it cannot interfere with other transactions by acquiring new locks.
Some common issues of 2PL are as follows:
- Deadlocks — A deadlock occurs when two or more transactions are waiting for each other to release locks, creating a cycle of dependencies that prevents any of them from proceeding.
- Cascading Rollbacks — This occurs when one transaction fails and rolls back, causing other dependent transactions to also roll back
- Loss in Serializability — While 2PL ensures serializability, it can limit concurrency because transactions must wait for locks to be released before they can proceed. This waiting can lead to lower throughput in high-concurrency environments.
As we understand the limitations of 2PL, let’s investigate on how MVCC can solve these problems.
HyPer’s MVCC Implementation#
In this post, we will mainly look at the MVCC patterns and techniques used in HyPer , which has inspired different concepts for other popular databases like DuckDB.
MVCC is the process of performing concurrent operations by maintaining different versions of the data in transaction linked buffers.
Snapshot Isolation#
To maintain Snapshot Isolation, each transaction operates on a snapshot of the database at a specific point in time. This prevents read-write conflicts and allows concurrent reads without blocking writes. However, while SI improves concurrency, it does not guarantee serializability — the highest level of isolation between transactions.
Serializability#
Serializability is a critical concept in database management systems (DBMS) that ensures the correctness and consistency of concurrent transactions. It guarantees that the outcome of executing multiple transactions concurrently is equivalent to some serial execution of those transactions, meaning they would produce the same results as if executed one after the other.
Undo and Redo buffers#
Let’s take the following example where we have 2 tables, Table 1 and Table 2 with their respective attributes in their initial state. The first column in both the tables are unique identifiers. In the diagram, we have defined the list of transactions that need to carry out. The format of the transactions is <timestamp> | [<table_name>:<attribute_identifier>:<attribute_value>] . So TS1 | T1:A:32 | T1:B:22 | T2:J:43 stands for changes to attribute A and B belonging to Table 1 and attribute J belonging to Table 2 at a timestamp of TS1 .
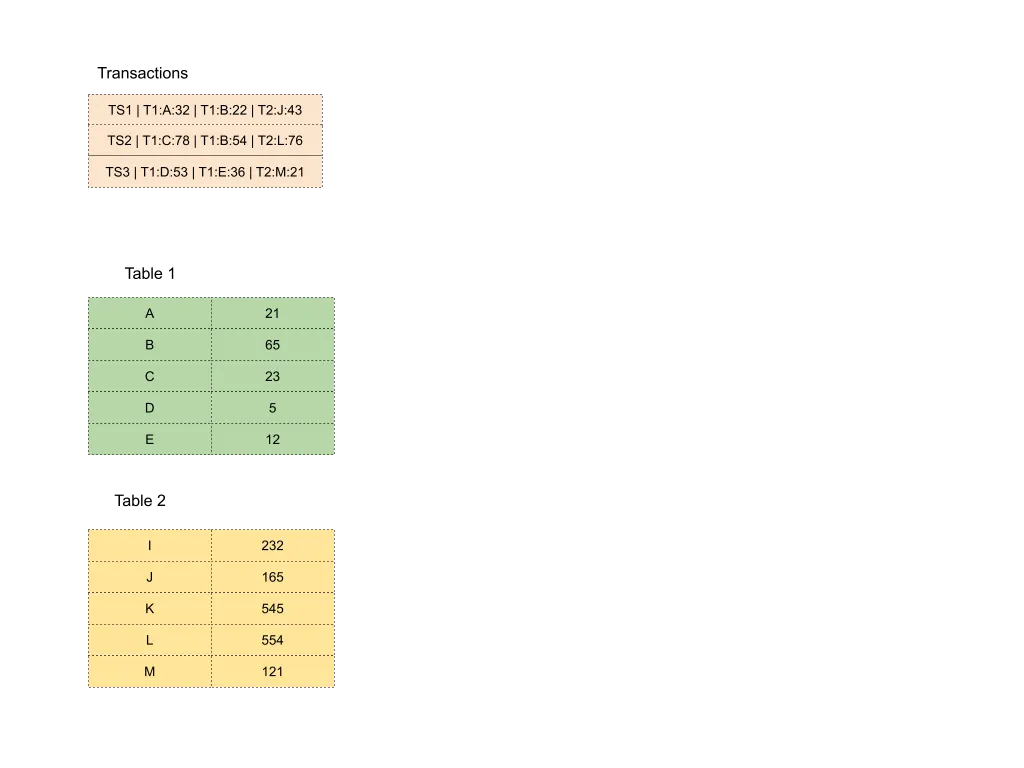
As we start performing the transactions, the attributes are changed in place and the version delta is stored in the Undo buffer of the transaction along with the timestamp at which the transaction was received. The Undo buffer is the representation of the attribute before the transaction operation was performed on the attribute. There are different formats of timestamps to differentiate between a version data change and a committed timestamp, which we will explain below.
In case the transaction has to be rolled back, the data in the Undo buffer is replaced in the attribute’s value. This results in a performance gain compared to other techniques as other techniques may result in a larger table lock in cases of transactions and rollbacks, whereas in this scenario, the scope of change is limited to only the changed attributes.
In cases of a SCAN or read operation during an ongoing transaction, the timestamp of the read operation is noted and the version matching the data before the timestamp is sent back to the user.
Transaction Validation#
Write-Write transactions are avoided entirely by looking at the version change of an attribute. In cases of conflicts for the same attribute, the write operation is delayed till the previous transaction has been validated and committed.
Once the transaction has made the required validations changes, the changes need to be committed. The validations needed to be done are again scoped to the changes in the transaction and doesn’t affect other attributes. In order to ensure a minimal scope of change, it uses Precision locking. A predicate tree is built for the different reads of the transaction. The read operations of a transaction are converted into predicates and is checked against the changed object’s undo buffers. If there are no overlaps of the predicates and the object’s unfo buffers, the transaction can proceed.
In order to avoid the read operations being affected by other recently committed transactions, which have been committed during the start time and commit time of the current transaction, the predicates of the ongoing transaction are cross checked with the before and after values of the other transactions as well. If there are no conflicts, then the transaction is deemed to be validated.
The changes are written to to a Redo Log which can then be used to rollback a transaction if required.
Garbage Collection#
As we have seen in the example above, the timestamp of the operations are used to determine which version of the change is to be used for a read or write operation. Depending on the latest committed timestamp, any buffers before that timestamp is garbage collected. Since the scope of the transactions are quite small, the garbage collection utilises minimal resources to removed the unreferenced and invalid versions.
Precision Locking#
To address the limitations of traditional MVCC implementations, researchers have introduced Precision Locking — an adaptation that enhances serializability validation without compromising performance. This technique focuses on validating that the extensional writes (actual changes) of recently committed transactions do not intersect with the intensional read predicates of a committing transaction.
Let’s consider a simplified example involving a bank database with a table named Accounts, which tracks customer account balances.Database Table: Accounts
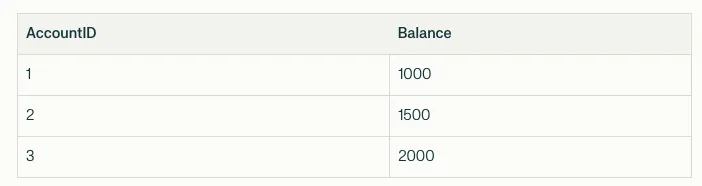
- Transaction T1: A customer wants to transfer $200 from Account 1 to Account 2.
- Transaction T2: Another customer wants to check if any accounts have a balance greater than $1200 and apply a bonus if they do.
Transaction T1 (Transfer)
- T1 reads the balance of Account 1 and Account 2.
- Before modifying the balances, T1 locks both accounts using precision locking.
- It checks that no other transactions are modifying these accounts.
- After confirming, it deducts $200 from Account 1 and adds it to Account 2.
Locked Data
- Locks are applied precisely to Accounts 1 and 2, ensuring that only these records are locked for the duration of the transaction.
Transaction T2 (Bonus Check)
- T2 queries for accounts with balances greater than $1200.
- Using precision locking, T2 locks only the relevant accounts that meet this criterion (in this case, Accounts 2 and 3).
- T2 reads the balances and finds that Account 2 now has $1700 (after T1’s transfer) and Account 3 has $2000.
- T2 applies a bonus to both accounts.
How Precision Locking Works
- Locking Mechanism: When T1 locks Accounts 1 and 2, it ensures that no other transaction can modify these records until T1 completes. However, other transactions can still read these records if they are not in conflict with the locked state.
- Conflict Detection: If another transaction (say T3) attempts to modify Account 1 while T1 is still executing, precision locking will prevent T3 from proceeding until T1 has completed. Conversely, if T3 is only reading Account 1, it can do so without being blocked.
- Reduced Lock Scope: Unlike traditional locking methods that might lock an entire table or broader set of records, precision locking focuses only on the necessary tuples (records) required for maintaining consistency. This allows for higher concurrency as more transactions can operate simultaneously without interference.
Synopses-Based Approach#
In addition to Precision Locking, HyPer employs a synopses-based approach using Versioned Positions to enhance scan performance for read-heavy workloads. By maintaining summaries of versioned record positions, HyPer can efficiently determine which data ranges to scan during analytical queries.
Few benefits of Synopses based approach
- High Scan Performance: By leveraging synopses, HyPer retains the high scan performance typical of single-version systems while still supporting concurrent transactions.
- Optimized Resource Utilization: The combination of positional delta trees and synopses allows for efficient memory usage and faster query processing times.
To illustrate how the synopses-based approach works in Multi-Version Concurrency Control (MVCC), let’s consider a simplified example involving a database table that stores information about products in an e-commerce application. We will walk through a scenario involving multiple transactions, focusing on how the synopses-based approach enhances read-heavy operations.
Let’s take a small example here.
Database Table: Products
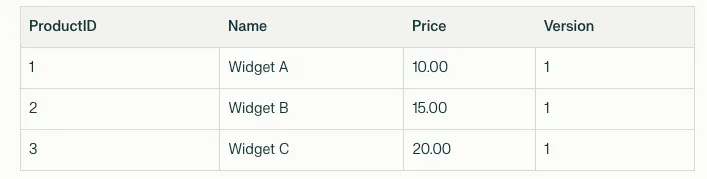
Assume we have three products in our database, each with an initial version (Version 1).
Transaction A: Update Product Price
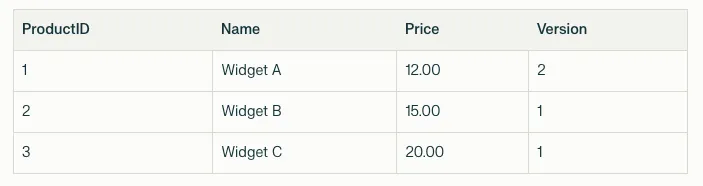
Transaction A starts and updates the price of “Widget A” from $10.00 to $12.00.
- In-Place Update: The system updates the price in place but also creates a before-image delta in an undo buffer to maintain the previous version.
- New Version Creation: The new version of “Widget A” is created, and the database now looks like this:
Transaction B: Read Products
While Transaction A is still ongoing, Transaction B starts and wants to read the prices of all products.
- Snapshot Isolation: Transaction B sees the database as it was at the start of its execution, which means it reads the original version of “Widget A” (Version 1) priced at $10.00, along with the current versions of “Widget B” and “Widget C”.
- Using Synopses-Based Approach:
- The synopses-based approach maintains metadata (synopses) about the positions of versions. For example, it might keep track of which versions are valid for each product based on their update timestamps.
- When Transaction B queries for all products, it uses this metadata to quickly access the relevant records without scanning through all versions unnecessarily.
Result of Transaction B
Transaction B retrieves:
- Widget A: $10.00 (Version 1)
- Widget B: $15.00 (Version 1)
- Widget C: $20.00 (Version 1)
Transaction A Commits
After completing its operations, Transaction A commits its changes, making Version 2 of “Widget A” permanent.
Garbage Collection
The system now performs garbage collection:
- It retains Version 2 of “Widget A” since it is the latest committed version.
- It can mark Version 1 for removal if no other transactions are accessing it.
References#
I hope you liked the article. Please let me know if you have any queries regarding the article. Happy reading!!